
Index란?
Index는 테이블에서 데이터의 위치를 가리키는 자료구조이다. Index가 없다면 원하는 데이터를 찾기 위해서 테이블 전체를 뒤져야 할 것이다.
이러한 Index는 크게 Clustered Index와 Non-Clustered Index 두 가지로 나눌 수 있다.
참고)
[DB] 인덱스(index)란? 인덱스 자료구조
인덱스(index)란? 인덱스란 데이터베이스 테이블의 검색 속도를 향상하기 위한 자료구조라고 할 수 있다. 책의 색인(index)을 보면 해당 내용이 어디에 있는지 알 수 있듯이 데이터의 인덱스를 참조
code-lab1.tistory.com
Clustered Index란?
clustered Index는 row의 물리적 정렬 순서를 설정하는 index 유형이다. clustered Index는 알파벳 순서대로 정렬되는 사전과 같다. 다음과 같은 Student 테이블이 있다고 하자.

해당 테이블의 Primary Key(PK)는 학생 번호이다. 이때 PK는 자동으로 clustered Index를 생성한다. 또한 Student 테이블은 자동으로 PK인 학생 번호에 따라 정렬된다.
이처럼 테이블의 PK는 자동으로 clustered Index를 생성하기 때문에 테이블에 PK를 지정한다면 PK에 따라 데이터가 정렬되게 된다.
이러한 clustered Index는 테이블 당 단 하나만 생성될 수 있다. 그렇다고 하나의 칼럼에만 생성될 수 있다는 뜻은 아니다. 왜냐하면 PK가 복합키일 수도 있기 때문이다.

[그림 2]와 같이 clustered Index가 없이 정렬되지 않은 테이블이 있다고 하자. 이 테이블은 내부적으로 아래와 같이 Data Page 단위로 저장된다.

[그림 3]과 같이 Data Page 단위로 데이터가 저장되어 있을 때, 학생번호가 6번인 데이터를 조회하고 싶다면 어떨까?
위 테이블은 학생번호로 정렬되어 있지 않기 때문에 몇 번 Data Page에 학생번호 6번인 데이터가 저장되어 있는지 알 수 없다. 따라서 1번 Data Page의 1행부터 순차적으로 데이터를 탐색하게 되는데, 이를 테이블 스캔(Table Scan)이라고 한다.
이때 학생번호를 PK로 지정한다고 하자. PK를 지정하면 해당 PK는 자동으로 Clustered Index를 생성하고 다음과 같은 In dex Page가 생성된다.

[그림 4]처럼 Index Page가 생성되는 과정은 다음과 같다.
1. 기존 Data Page의 데이터들이 PK인 '학생번호'를 기준으로 정렬되어 새로운 Data Page에 저장된다.
2. Index Page라는 별도의 Page가 생성되고, 각각의 Data Page 번호와 해당 Data Page의 첫 번째 데이터가 Index Page에 저장된다.
3. 기존의 Data Page는 삭제된다.
이때 Index Page는 Root Page, Data Page들은 Leaf Page라고 부른다.
이제 다시 학생번호가 6번인 데이터를 조회하려면 어떻게 할까?

1. Index Page에서 '학생번호 6'은 5보다는 크고 9보다는 작으므로 Data Page 5에 있음을 확인한다.
2. Data Page 5를 찾아가 차례대로 데이터를 뒤져 '학생번호 6'인 데이터를 찾는다.
이러한 탐색을 인덱스 스캔(Index Scan)이라고 한다. 인덱스 스캔은 특정 리프 페이지만을 탐색하므로 전체 Data Page 탐색하는 테이블 스캔보다 탐색 속도가 훨씬 빠르다.
Non-Clustered Index란?
Clustered Index로 정렬된 테이블에서 Clustered Index를 기준으로 데이터를 탐색하면 빠른 속도로 데이터를 조회할 수 있다. 하지만 Clustered Index가 아닌 칼럼으로 데이터를 조회한다면 어떨까?
예를 들어 위 예제에서 학생번호가 아닌 이름으로 데이터를 조회하면 어떨까? 이때는 인덱스화된 Data Page들을 처음부터 끝까지 탐색하며 데이터를 찾을 것이다. 이를 전체 인덱스 스캔(Full Index Scan)이라고 한다.
이때 이름을 기준으로 다시 Clustered Index를 설정하면 Data Page 자체를 새로 생성해 정렬할 것이다.
이처럼 Clustered Index는 테이블 당 하나밖에 설정하지 못한다는 큰 단점이 존재한다.
이를 해결할 수 있는 게 바로 Non-Clustered Index이다. 위 예제에서 '이름'을 기준으로 Non-Clustered Index를 생성한다고 하자.

Non-Clustered Index는 Data Page를 그대로 두고 '이름'을 기준으로 정렬된 Index Page를 별도로 생성한다. Clustered Index와 마찬가지로 Root Page는 각각의 Leaf Page들의 시작 주소를 가지고 있다.
또한 각각의 Leaf Page들은 RID(Row Identifier) [파일번호 : Data Page 번호 : Row 번호]를 가진다.
예를 들어 '김태희'의 RID를 보면 '1번 파일의 3번 Data Page의 1행'에 존재한다는 사실을 알 수 있다.
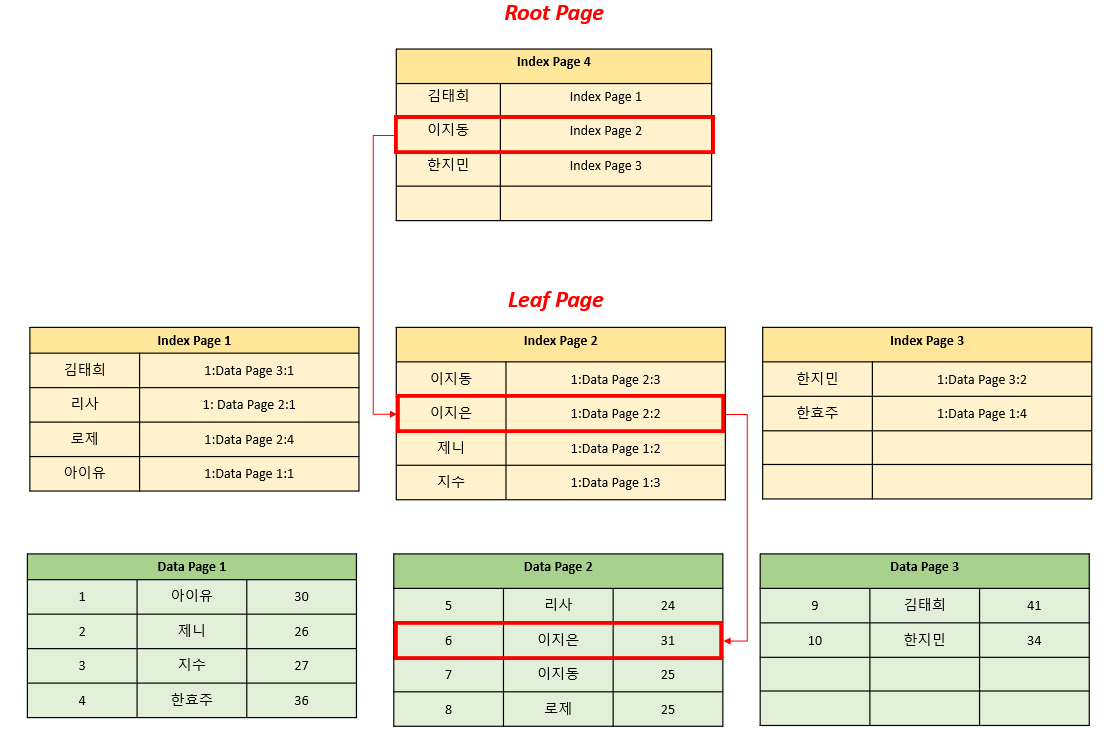
이제 이름이 '이지은'인 데이터를 조회한다고 하자. 아래와 같은 과정을 거치게 된다.
1. Root Page에서 '이지은'을 탐색한다. '이지동'보다는 뒤, '한지민'보다는 앞이므로 Index Page 2를 찾아간다. 이 과정을 Index Seek라고 한다.
2. Leaf Page에서 RID를 보고 실제 데이터가 저장되어 있는 Data Page를 찾아간다. 이 과정을 RID Lookup이라고 한다.
Clustered Index가 단일 포인터라면 Non-Clustered Index는 이중 포인터라고 비유해도 좋겠다.
이러한 Non-Clustered Index는 한 테이블 당 여러 개를 생성할 수 있다. 하지만 인덱스 페이지를 위한 별도의 공간이 필요하다.
비교
| Clustered Index | Non-Clustered Index |
| 테이블당 하나만 생성 가능 | 테이블 당 여러개 생성 가능 |
| 탐색 속도가 상대적으로 빠르다 | 탐색 속도가 상대적으로 느리다 |
| 상대적으로 메모리를 덜 차지 한다 | 상대적으로 메모리를 많이 차지한다(인덱스 페이지를 위한 별도의 공간이 필요하므로) |
참고
1. https://byjus.com/gate/difference-between-clustered-and-non-clustered-index/
2. https://pangtrue.tistory.com/286
'Computer Science > [DB]' 카테고리의 다른 글
| [DB] 제 4정규형과 제 5정규형, 4NF와 5NF (4) | 2022.11.01 |
|---|---|
| [DB] OLTP란? OLAP란? DSS란? OLTP와 OLAP의 차이 (0) | 2022.10.20 |
| [DB] 데이터베이스 트리거(Trigger)란? (0) | 2022.09.05 |
| [DB] 리플리케이션(Replication)이란? 클러스터링(Clustering)이란? (1) | 2022.04.19 |
| [DB] 파티셔닝(Partitioning)이란? 샤딩(Sharding)이란? 파티셔닝과 샤딩의 차이점 (0) | 2022.04.12 |